
Here CodeAvail experts will explain to you what is EM Algorithm in machine learning and how it works.
EM Algorithm and Machine Learning
Table of Contents
In reality utilization of Machine Learning, it is basic that there are numerous applicable highlights accessible for learning. However, just a little subset of them is noticeable. In this way, for the factors which are now and sometimes noticeable and sometimes not. At that point, we can utilize the occasions. When that variable is accessible is seen to learn and afterward anticipate. Its purpose in the occurrences when it isn’t observable.
Then again, the Expectation-Maximization algorithm(EM) can be utilized for the dormant (factors that are not easily recognizable. And are really gathered from the estimations of the other observed factors). In order to anticipate their qualities with the condition that the general type of probability distribution overseeing those inactive factors is known to us.
Expectation-Maximization algorithm is really at the base of numerous unaided clustering algorithms in the Machine learning field. It was clarified, proposed, and given its name in a paper distributed in 1977 by Arthur Dempster, Nan Laird, and Donald Rubin. It is utilized to determine the nearby greatest probability parameters of a statistical model in situations. Where dormant factors are included and the information is absent or deficient.
In this article, we have given all the essential information regarding what is EM algorithm in machine learning.
What is EM Algorithm In Machine Learning?
Expectation-Maximization algorithm was introduced in 1997 by Arthur Dempster, Nan Laird, and Donald Rubin. It is utilized to find the local maximum statistical model probability parameters. In case the possible variables are existing or the data is missing or inadequate.
The Expectation-Maximization Algorithm supports the following steps to determine the appropriate model parameters in the presence of latent variables.
- Analyze a collection of exciting parameters in inadequate data.
- Expectation Step – This step is utilized to determine the values of the lost values in the data. It includes the recognized data to guess the values in the lost data.
- Maximization Step – This step makes whole data after the Expectation step updates the lost values in the data.
- Perform the step Expectation Step and Maximization Step until the convergence is met.
Convergence– The idea of union in likelihood depends on the intuition. Suppose we have two irregular factors if the likelihood of their distinction is little, it is supposed to be converged. For this situation, convergence implies if the qualities coordinate one another.
Since we understand what is the Expectation-Maximization algorithm in Machine Learning. Let us investigate how it really functions.
How Does EM Algorithm Work?
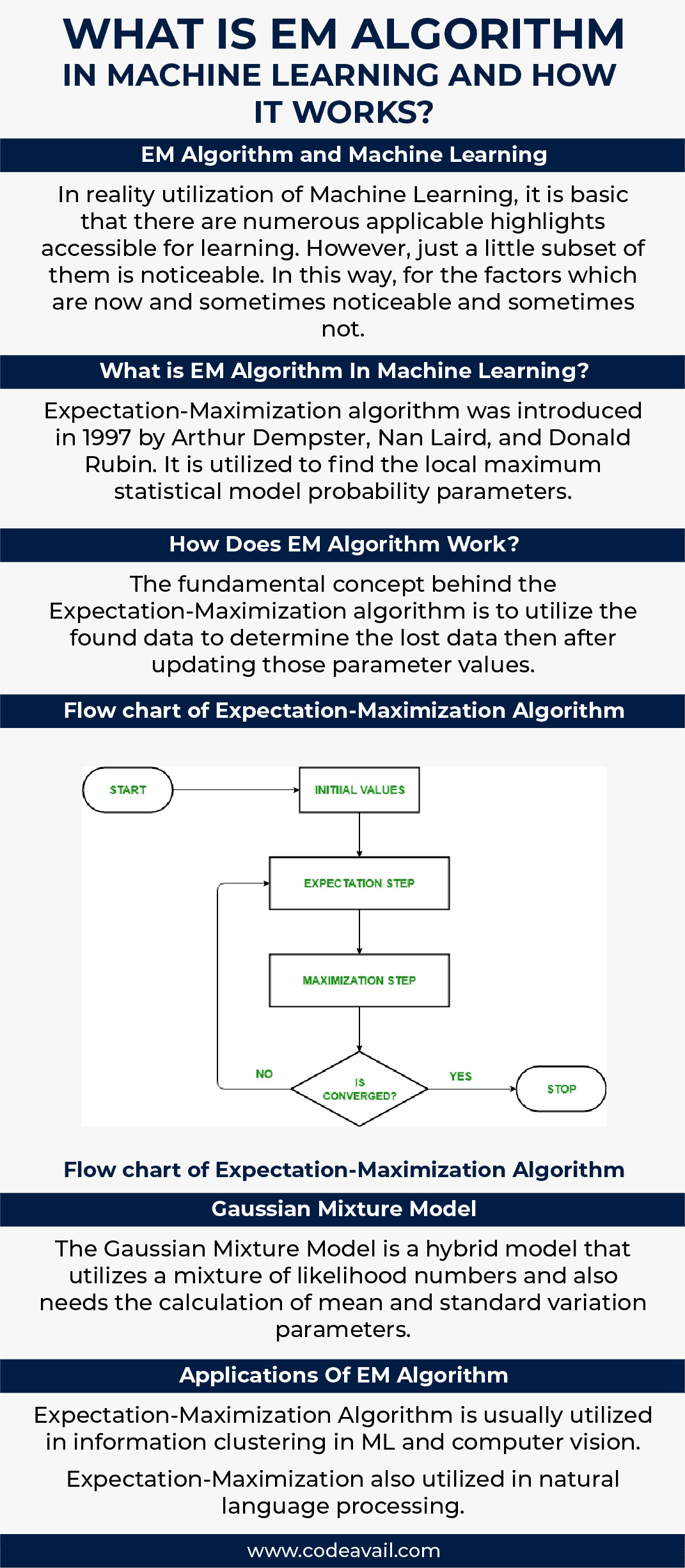
The fundamental concept behind the Expectation-Maximization algorithm is to utilize the found data to determine the lost data then after updating those parameter values. Above we have discussed what is EM algorithm in Machine learning now having the flowchart in mind. Let us know how the Expectation-Maximization algorithm works.
- In the opening stage, a collection of primary parameters is examined. A set of incomplete and unobserved data is provided to the system with an assumption that the detected data is coming from a particular form.
- After that next step is the Expectation Step or E-STEP. In this stage, you use the detected data to determine lost or inadequate data. It is utilized to update the variables.
- Then the next step is the Maximization step or M-STEP is utilized to create the data produced in the E-STEP. This step performs the hypothesis updation.
- In the final step, it is verified whether the values are converging or not. If the values match, then there is no need to do anything, else we will proceed with the Expectation Step and Maximization step until the convergence is met.
Flow chart of Expectation-Maximization Algorithm

Gaussian Mixture Model
The Gaussian Mixture Model is a hybrid model that utilizes a mixture of likelihood numbers and also needs the calculation of mean and standard variation parameters.
Even though there are many ways to determine the Gaussian Mixture Model parameters, the most popular method is the Maximum Probability estimation.
Let us suppose a case, where the information points are created by two distinct procedures, and each procedure has a Gaussian likelihood distribution. Be that as it may, it is confusing, which dissemination a given information point belongs to since the information is connected and distribution is comparable.
What’s more, the procedures utilized for creating the information points represent the inactive factors and impact the information. The EM algorithm appears the best way to deal with measure the parameters of the distributions.
Applications Of EM Algorithm
- Expectation-Maximization Algorithm is usually utilized in information clustering in ML and computer vision.
- Expectation-Maximization also utilized in natural language processing.
- The Expectation-Maximization algorithm is utilized for estimation of the parameter in mixed models and quantitative genetics
- It is utilized in psychometrics for determining item parameters and potential capabilities of item response theory models.
- other applications incorporate medical image restoration, structural engineering, etc.
Uses of Expectation-Maximization algorithm –
- EM can be utilized to fulfill the lost data in a sample.
- Expectation-Maximization can be utilized as the basis of unsupervised knowledge of clusters.
- It can be utilized to determine the parameters of the Hidden Markov Model (HMM).
- It can be utilized for determining the values of the latent variables.
Advantages of Expectation-Maximization algorithm –
- Expectation-Maximization always guarantees that probability will grow with each iteration.
- The Expectation-step and Maximization-step are usually pretty simple for several problems in times of implementation.
- Answers to the Maximization-steps usually exist in the concluded form.
Disadvantages of Expectation-Maximization algorithm –
- Expectation-Maximization has late convergence.
- EM performs convergence to the limited optima only.
- It needs both the possibilities, backward and forward (numerical optimization needs only forward possibility).
Conclusion
To this end, we have included all the relevant information regarding your problem,” what is EM algorithm in machine learning”. We hope that you find this article helpful.
However, if you come across any problem regarding Expectation-Maximization in machine learning you can contact us anytime and from anywhere in the world. As we are always available for your service.
If you want to get machine learning assignment help and algorithm assignment help, you can ask our experts to submit their queries.

